Ver código
library(data.table) # nos interesa la función fread para levantar el CSV
library(tidyverse) #un clásico
library(stringr) # para limpiar y acomodar el dataframe
library(ggplot2) # (L)
library(artyfarty) # para customizar los gglots
El presente documento electrónico es un ejercicio abierto de extracción, sistematización y visualización de los resultados del recuento provisional de las Elecciones Primarias, Abiertas, Simultaneas y Obligatorias en Argentina (PASO 2021). Lo armé originalmente para el encuentro Cómo empezar? de R-Ladies y NIS realizado en 20211, y lo cierto es que como nunca lo publiqué en ninguno de los espacios para los que escribo, me pareció interesante compartirlo aquí, ya que próximamente se llevarán adelante las Elecciones Nacionales, por medio de las cuales los argentinos y argentinas elegiremos Presidente.
Para consultar los datos de las PASO debemos acceder al portal del Estado Nacional donde se encuentra publicado el recuento provisorio: https://www.argentina.gob.ar/elecciones/resultados-del-recuento-provisional-de-las-elecciones-paso. Aquí encontraremos los resultados de las elecciones por provincia (y sección para el caso de Buenos Aires).
En esta oportunidad nos invito a conocer cuáles fueron los resultados de las elecciones PASO para la categoría concejal en mi ciudad: Lanús, Provincia de Buenos Aires, correspondiente a la tercera sección electoral.

Es importante destacar que a los fines expositivos de este documento no vamos a leer los datos localmente, sino que los consultaremos de manera remota conectándonos mediante el siguiente enlace: https://www.argentina.gob.ar/interior/dine/elecciones2021/resultados-del-recuento-provisional-de-las-elecciones-paso
Vamos a levantar las librerías que utilizaremos para nuestra consulta:
library(data.table) # nos interesa la función fread para levantar el CSV
library(tidyverse) #un clásico
library(stringr) # para limpiar y acomodar el dataframe
library(ggplot2) # (L)
library(artyfarty) # para customizar los gglotsVamos a descargar el set de datos de los votos correspondiente a la tercera sección electoral de la Provincia de Buenos Aires.
Lo que observaremos inicialmente es que dicho enlace nos remite a un archivo comprimido zip, pero en vez de descargarlo y descomprimirlo manualmente, lo vamos a hacer de manera automática con R. Veamos cómo:
activity_url <- "https://argentina.gob.ar/sites/default/files/buenos_aires_tercera.zip" #definimos una variable activity_url que contiene la URL del archivo zip que queremos descargar.
temp <- tempfile() #Creamos un archivo temporal en el sistema de archivos local. Este archivo se utilizará más tarde para descargar y descomprimir el archivo zip.
download.file(activity_url, temp) #Descarga el archivo zip de la URL especificada y lo guarda en el archivo temporal que acabamos de crear.
unzip(temp, "Buenos Aires_Tercera.csv") #Descomprimimos el archivo zip y extrae el archivo CSV con el nombre "Buenos Aires_Tercera.csv". Este archivo se guarda en el directorio de trabajo actual.
ba_tercera <- fread("Buenos Aires_Tercera.csv", sep=";") #Leemos el archivo CSV recién descargado en R utilizando la función fread() de la librería data.table.
#La opción sep=";" especifica que el separador de campo utilizado en el archivo CSV es el punto y coma.
unlink(temp) #Elimina el archivo temporal que creamos anteriormente para descargar y descomprimir el archivo zip.Con la función summary obtendremos una descripción rápida y por eso no menos detallada de los datos que descargamos. Nos devuelve estadísticas descriptivas para cada variable, lo cual nos permite entender rápidamente la distribución, el rango y la variabilidad de los datos.
summary(ba_tercera)Siempre que nos encontramos con un nuevo set de datos es importante tener una primera vista de su estructura para ver si efectivamente contiene lo que nos interesa.
Otra librería interesante para explorar nuestra data recién llegada es skim, del paquete skimr.
library(skimr)
skim(ba_tercera)| Name | ba_tercera |
| Number of rows | 1107503 |
| Number of columns | 19 |
| Key | NULL |
| _______________________ | |
| Column type frequency: | |
| character | 11 |
| numeric | 8 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| Agrupacion | 0 | 1 | 0 | 46 | 191690 | 36 | 0 |
| Cargo | 0 | 1 | 10 | 22 | 0 | 3 | 0 |
| Distrito | 0 | 1 | 12 | 12 | 0 | 1 | 0 |
| Establecimiento | 0 | 1 | 10 | 64 | 0 | 1439 | 0 |
| Fecha | 0 | 1 | 16 | 16 | 0 | 422 | 0 |
| IdCircuito | 0 | 1 | 5 | 5 | 0 | 189 | 0 |
| SeccionProvincial | 0 | 1 | 15 | 15 | 0 | 1 | 0 |
| Mesa | 0 | 1 | 6 | 6 | 0 | 3126 | 0 |
| Seccion | 0 | 1 | 5 | 18 | 0 | 19 | 0 |
| lista | 0 | 1 | 0 | 34 | 191690 | 53 | 0 |
| tipoVoto | 0 | 1 | 5 | 10 | 0 | 6 | 0 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| Codigo | 0 | 1.00 | 12741.67 | 10314.33 | 3689 | 6065 | 8129 | 13166 | 50180 | ▇▁▂▁▁ |
| IdCargo | 0 | 1.00 | 5.22 | 1.73 | 3 | 3 | 6 | 7 | 7 | ▇▁▁▇▇ |
| IdDistrito | 0 | 1.00 | 2.00 | 0.00 | 2 | 2 | 2 | 2 | 2 | ▁▁▇▁▁ |
| IdSeccion | 0 | 1.00 | 52.29 | 33.48 | 3 | 17 | 61 | 70 | 132 | ▅▂▇▂▁ |
| idAgrupacion | 191690 | 0.83 | 362.96 | 193.19 | 8 | 258 | 320 | 506 | 911 | ▃▇▇▁▁ |
| idAgrupacionInt | 191690 | 0.83 | 32.58 | 11.27 | 15 | 22 | 31 | 43 | 80 | ▇▆▅▁▁ |
| idLista | 191690 | 0.83 | 1.87 | 1.26 | 1 | 1 | 1 | 2 | 7 | ▇▁▁▁▁ |
| votos | 0 | 1.00 | 8.12 | 19.72 | 0 | 0 | 1 | 5 | 230 | ▇▁▁▁▁ |
Al chequear nuestros datos nos encontraremos con más de un millón de observaciones y 19 variables correspondiente a los resultados de las PASO por municipio (de la tercera sección), lista en pugna, agrupaciones y escuelas donde votaron lxs ciudadanxs.
Ahora que verificamos que la data está ok, haremos una serie operaciones para generar una estadística descriptiva que de cuenta de la compulsa electoral para la categoría “concejal” en Lanús.
Nos interesa generar un cuadro de 6 columnas que aloja los votos totales y porcentuales por agrupación (partidos) y lista (sub-categorías dentro de las agrupaciones). Para ello, una estrategia, de muchas posibles, es armar dos cuadros que después uniremos para obtener los datos tal cual los queremos.
# Seleccionamos las filas donde el valor de la columna "Cargo" es "CONCEJALES" y creamos un nuevo objeto "lanus_listas" que se basa en la tabla "ba_tercera".
lanus_listas <- ba_tercera %>%
filter(Cargo == "CONCEJALES") %>%
# Filtramos solamente las filas donde el valor de la columna "Seccion" es "Lanús".
filter(Seccion == "Lanús") %>%
# Seleccionamos las columnas "Agrupacion", "lista", "tipoVoto" y "votos".
select(Agrupacion, lista, tipoVoto, votos) %>%
# Creamos una nueva columna llamada "tipo_voto" que se basa en la columna "tipoVoto".
# Si el valor de "tipoVoto" es "blancos", entonces el valor de "tipo_voto" es "blancos".
# Si el valor de "tipoVoto" es cualquiera de los valores en el vector c("nulos", "recurridos", "impugnados", "comando"), entonces el valor de "tipo_voto" es "nulos".
# Si el valor de "tipoVoto" es "positivo", entonces el valor de "tipo_voto" es "positivo".
mutate(tipo_voto = case_when(
tipoVoto %in% "blancos" ~ "blancos",
tipoVoto %in% c("nulos", "recurridos", "impugnados", "comando") ~ "nulos",
tipoVoto %in% "positivo" ~ "positivo"
)) %>%
# Agrupamos las filas de la tabla según los valores de las columnas "Agrupacion", "lista" y "tipo_voto".
group_by(Agrupacion, lista, tipo_voto) %>%
# Calculamos el total de votos para cada combinación de "Agrupacion", "lista" y "tipo_voto".
summarise(votos_lista = sum(votos)) %>%
# Eliminamos la palabra "positivo" de cualquier valor en las columnas que sean de tipo caracter (texto). dejamos lugares vacios para completar luego.
mutate(across(where(is.character), str_remove_all, pattern = fixed("positivo")))Terminamos de acomodar el dataset para obtener en una misma columna las etiquetas de partidos políticos, más las de votos en blanco y nulos, para eso vamos a concatenar los datos de lista|agrupación y tipo_voto.
# Creamos la variable "listas" concatenando las columnas "lista" y "tipo_voto"
lanus_listas$listas <- paste(lanus_listas$lista, lanus_listas$tipo_voto)
# Creamos la variable "agrupaciones" concatenando las columnas "Agrupacion" y "tipo_voto"
lanus_listas$agrupaciones <- paste(lanus_listas$Agrupacion, lanus_listas$tipo_voto)
# Agrupamos por la variable "agrupaciones" y sumamos los votos de las listas de cada agrupación,
# luego creamos una variable "totales" que almacena la suma total de votos por agrupación
# y calculamos el porcentaje de votos de cada agrupación
lanus_agrupaciones <- lanus_listas %>%
group_by(agrupaciones) %>%
summarise(votos_agrupacion=sum(votos_lista)) %>%
mutate(totales=sum(votos_agrupacion),
porc_agrupacion=1e2*votos_agrupacion/totales)
# Combinamos la tabla "lanus_listas" con la tabla "lanus_agrupaciones" utilizando la variable "agrupaciones",
# y calculamos el porcentaje de votos de cada lista en su agrupación
# Finalmente, seleccionamos las variables que nos interesan
lanus_concejales <- lanus_listas %>%
left_join(lanus_agrupaciones, by="agrupaciones") %>%
mutate(porc_lista=1e2*votos_lista/votos_agrupacion) %>%
ungroup() %>%
select(agrupaciones, listas, votos_agrupacion,
votos_lista, porc_agrupacion, porc_lista)Nuestra data ahora se ve así.
library(gt) # Cargar la biblioteca "gt" para la creación de tablas
lanus_concejales %>% # Seleccionar el conjunto de datos "lanus_concejales"
ungroup() %>% # Desagrupar cualquier agrupación de filas que se haya realizado anteriormente
arrange(desc(votos_agrupacion)) %>% # Ordenar las filas en orden descendente según la columna "votos_agrupacion"
gt() # Crear una tabla utilizando la biblioteca "gt"| agrupaciones | listas | votos_agrupacion | votos_lista | porc_agrupacion | porc_lista |
|---|---|---|---|---|---|
| FRENTE DE TODOS | CELESTE Y BLANCA 2 | 97929 | 22070 | 38.3306261 | 22.53674 |
| FRENTE DE TODOS | CELESTE Y BLANCA 4 | 97929 | 42289 | 38.3306261 | 43.18333 |
| FRENTE DE TODOS | CELESTE Y BLANCA 6 | 97929 | 33570 | 38.3306261 | 34.27994 |
| JUNTOS | A | 94807 | 70601 | 37.1086365 | 74.46813 |
| JUNTOS | DAR EL PASO | 94807 | 24206 | 37.1086365 | 25.53187 |
| FRENTE DE IZQUIERDA Y DE TRABAJADORES - UNIDAD | (R)EVOLUCIONEMOS LA IZQUIERDA | 12914 | 2379 | 5.0546999 | 18.42187 |
| FRENTE DE IZQUIERDA Y DE TRABAJADORES - UNIDAD | UNIDAD DE LA IZQUIERDA | 12914 | 10535 | 5.0546999 | 81.57813 |
| blancos | blancos | 12674 | 12674 | 4.9607609 | 100.00000 |
| AVANZA LIBERTAD | LIBERTAD | 12205 | 7233 | 4.7771885 | 59.26260 |
| AVANZA LIBERTAD | REPUBLICANOS UNIDOS | 12205 | 4972 | 4.7771885 | 40.73740 |
| FRENTE VAMOS CON VOS | HAY OTRO CAMINO | 8571 | 4219 | 3.3547958 | 49.22413 |
| FRENTE VAMOS CON VOS | OTRO CAMINO | 8571 | 4352 | 3.3547958 | 50.77587 |
| nulos | nulos | 4078 | 4078 | 1.5961798 | 100.00000 |
| UNION CELESTE Y BLANCO | + VALORES | 2655 | 2655 | 1.0392000 | 100.00000 |
| MOVIMIENTO AL SOCIALISMO | PARA RENOVAR A LA IZQUIERDA | 2012 | 2012 | 0.7875218 | 100.00000 |
| REPUBLICANO FEDERAL | PRINCIPIOS Y VALORES | 1766 | 1766 | 0.6912343 | 100.00000 |
| UNION POR TODOS | UNIDAD | 1525 | 1525 | 0.5969039 | 100.00000 |
| FRENTE PATRIOTA | PRIMERO LA PATRIA | 1121 | 1121 | 0.4387733 | 100.00000 |
| FEDERAL | CELESTE Y BLANCA | 825 | 825 | 0.3229152 | 100.00000 |
| TODOS POR BUENOS AIRES | TODOS POR LA PROVINCIA | 783 | 783 | 0.3064759 | 100.00000 |
| HUMANISTA | NARANJA | 717 | 717 | 0.2806427 | 100.00000 |
| RENOVADOR FEDERAL | SOMOS RENOVADORES | 470 | 470 | 0.1839638 | 100.00000 |
| CONSERVADOR POPULAR | UNICA | 433 | 433 | 0.1694816 | 100.00000 |
Generamos una tabla de los resultados con gt, una biblioteca de R que permite crear tablas de una manera muy fácil y personalizable. La abreviación “gt” significa “grammar of tables” (gramática de tablas), lo que refleja la filosofía detrás de la biblioteca, que es la de proporcionar una sintaxis fácil y consistente para crear y dar formato a tablas.
“gt” nos da varias opciones para personalizar la apariencia de las tablas, tales como agregar filas y columnas de encabezado, formatear los valores de las celdas, agregar estilos CSS, y mucho más. Además, “gt” puede producir tablas en varios formatos, incluyendo HTML, Markdown, LaTeX, y otros.
Para finalizar vamos a graficar nuestro trabajo recuperando la performance electoral de las fuerzas políticas más votadas en el municipio.
Primero imprimiremos el porcentual de votos por agrupación:
p <- lanus_concejales%>%
select(agrupaciones, porc_agrupacion) %>%
distinct()%>%
filter(porc_agrupacion>1) %>%
arrange(porc_agrupacion) %>%
mutate(agrupaciones= fct_recode(agrupaciones,
"FIT"= "FRENTE DE IZQUIERDA Y DE TRABAJADORES - UNIDAD "))%>%
mutate_if(is.numeric, round, digits=1)%>%
ggplot(aes(x = reorder(agrupaciones, +porc_agrupacion, sum),
y = porc_agrupacion, fill = agrupaciones)) +
geom_bar(stat = "identity")+
coord_flip()+
geom_text(aes(label=porc_agrupacion),
position=position_dodge(width=0.1), vjust=-0.25,
size = 2, lineheight=.7, margin=margin(-15,5,5,10))+
ggtitle("PASO 2021 Lanús: Porcentaje de votos por agrupación política para la categoría concejal.") +
labs(x= "Agrupación",
y= "% votos por agrupación",
fill = "Agrupaciones",
caption = "Fuente: datos abiertos de la Dirección Nacional Electoral.")+
theme(plot.title = element_text(hjust = 0.5, size = 9,
lineheight=.7, face="bold",
margin=margin(15,15,15,15)),
axis.text.x = element_text(angle = 45, size = 5),
axis.title.x = element_text(size = 7),
axis.title.y = element_text(size = 7),
axis.text.y = element_text(size = 7),
plot.caption = element_text(hjust = 0, face = "italic", size = 6),
legend.title = element_text(color = "black", size = 6),
legend.text = element_text(color = "black", size = 5),
legend.position="right")
p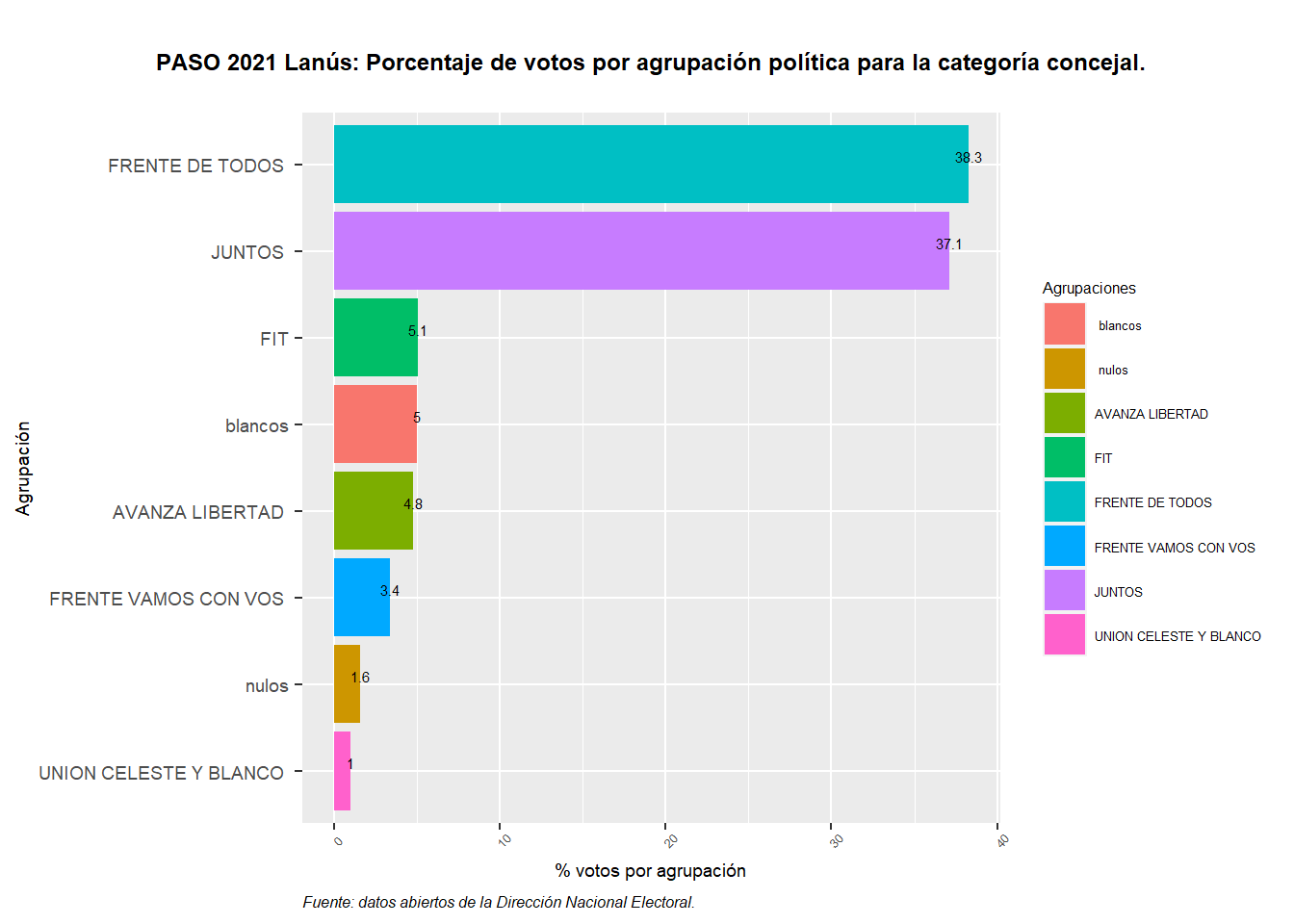
Por último generaremos un gráfico de paneles customizado en ggplot (potenciado con la librería artyfarty) que refleja los votos que obtuvieron las distintas listas dentro las principales fuerzas contendientes en el Municipio, el objetivo es ver conocer qué porcentaje obtuvo cada fracción.
p <- lanus_concejales%>%
filter(votos_agrupacion>12900) %>%
mutate(agrupaciones= fct_recode(agrupaciones,
"FIT"= "FRENTE DE IZQUIERDA Y DE TRABAJADORES - UNIDAD "))%>%
mutate_if(is.numeric, round, digits=1)%>%
ggplot(aes(x = reorder(listas, +porc_lista, sum),
y = porc_lista, fill = agrupaciones)) +
geom_bar(stat = "identity")+
geom_text(aes(label=porc_lista),
position=position_dodge(width=0.1), vjust=-0.25,
size = 2, lineheight=.7, margin=margin(-15,0,0,0))+
ggtitle("PASO 2021 Lanús: Porcentaje de votos a concejal por lista, según agrupación política") +
scale_fill_manual(values = pal("d3js"))+
labs(x= "Listas",
y= "% Votos por lista.",
fill = "Agrupaciones",
caption = "Fuente: datos abiertos de la Dirección Nacional Electoral.")+
theme(plot.title = element_text(hjust = 0.5, size = 9,
lineheight=.7, face="bold",
margin=margin(15,15,15,15)),
axis.text.x = element_text(angle = 45, size = 5,
margin=margin(-15,-15,-15,-15)),
axis.title.x = element_text(size = 7,
margin=margin(-15,-15,-15,-15)),
axis.title.y = element_text(size = 7),
axis.text.y = element_text(size = 7),
plot.background=element_rect(fill = "#fefdf6"),
panel.background = element_rect(fill = '#F0EDE3'),
panel.grid.major = element_line(colour = "#b4d9cf"),
strip.background = element_rect(fill="#b4d9cf"),
plot.caption = element_text(hjust = 0, face = "italic", size = 6,
margin=margin(20,20,20,20)),
legend.title = element_text(color = "black", size = 6),
legend.text = element_text(color = "black", size = 5),
legend.position="right")+
facet_wrap(~agrupaciones, scales = "free", ncol = 3)
p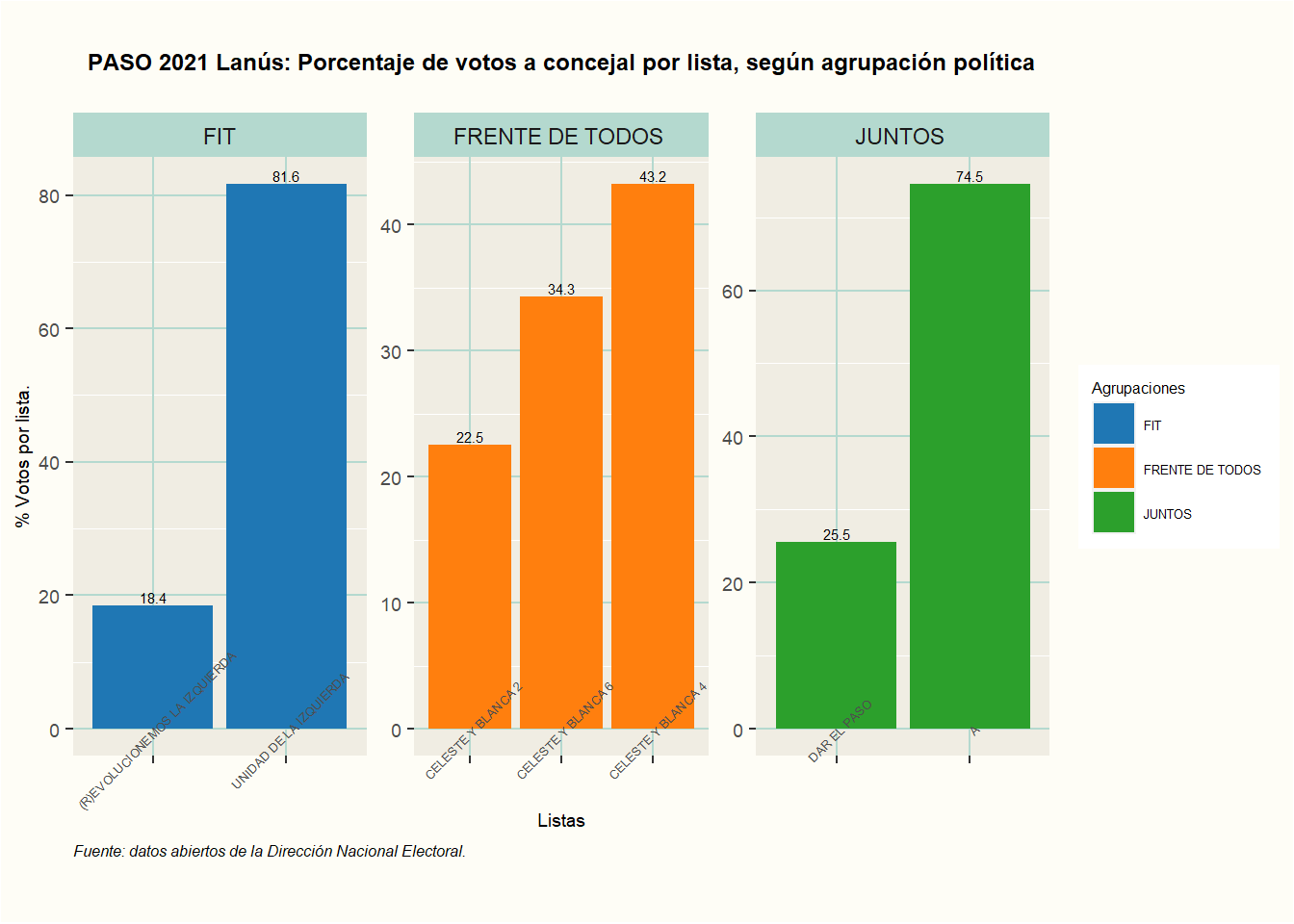
Podríamos seguir ordenando los datos para las distintas categorías de la elección, prestando atención por ejemplo al caso de diputadxs nacionales, provinciales, como así también a la posibilidad de filtrar los resultados por Provincia, Municipio, o Escuela…pero eso quedará para que puedas replicarlo en tu computadora con el ejemplo que vimos.
Siguiendo la línea de trabajo presentada en este documento armé en RShiny un visor interactivo que permite explorar los resultados de las Elecciones Legislativas 2021 para la categoría Diputado/a Nacional en el Conurbano Bonaerense según corredor de referencia (sur, oeste, norte). La propuesta aquí es dar cuenta de los matices de la preferencia electoral, indagando en cómo se dirime la puja FDT-JUNTOS a escala territorial, para lo cual se extraen y visualizan en pantalla los datos de victorias de ambas fuerzas calculando los votos positivos por circuito electoral.
La aplicación puede consultarse full haciendo click aquí.
Hasta aquí llegamos, nos leemos la próxima!
Encuentran la data de la actividad aquí, y el código original que presenté durante mi exposición está subido en este repositorio.↩︎
@online{damian_orden2023,
author = {Damian Orden, Pedro},
title = {Explorando Los Resultados de Las {PASO} 2021},
date = {2023-05-08},
url = {https://tecysoc.netlify.app/posts/paso 2021/},
langid = {en}
}